










In February, OpenAI made a big splash with the unveiling of Sora, an impressive AI tool that can transform text prompts into engaging videos. With Sora, users can breathe life into their ideas, watching as the AI crafts dynamic 60-second videos from brief text cues. But another player in town has been making waves on the internet: VideoPoet, a video generation tool from Google that hit the scene three months prior.
VideoPoet is the brainchild of a team of 31 researchers at Google Research, and it’s a game-changer in the world of multimedia creation. While Sora focuses on turning text into visual stories, VideoPoet takes a different approach. It excels at creating realistic videos using text, images, or even existing video footage, thanks to advanced techniques like autoregressive language modeling and tokenizers such as MAGVIT V2 and SoundStream. This versatility opens up a world of possibilities for digital art, film production, and interactive media.

Source: Google Research
What makes VideoPoet stand out is its unique architecture. While many video generation models rely on diffusion-based methods, which are considered top performers in the field, Google Research took a different route. Instead of using the popular Stable Diffusion model, Google Researchers opted for a large language model (LLM) based on the transformer architecture. This type of AI model, typically used for text and code generation, has been repurposed to generate videos—a bold move that sets VideoPoet apart from the crowd.
“Most existing models employ diffusion-based methods that are often considered the current top performers in video generation. These video models typically start with a pretrained image model, such as Stable Diffusion, that produces high-fidelity images for individual frames, and then fine-tune the model to improve temporal consistency across video frames,” Google Research team wrote in their pre-review research paper.
What is VideoPoet and how does it work?
At its core, VideoPoet uses an autoregressive language model to learn from various modalities such as video, image, audio, and text. This is made possible by employing multiple tokenizers—MAGVIT V2 for video and image, and SoundStream for audio.
When the model generates tokens based on a given context, these tokens are later converted back into a visible representation using the decoder of the respective tokenizer. This allows for seamless translation between different forms of media, ensuring a cohesive and comprehensive understanding across all modalities. Below are the components of VideoPoet:
- Pre-trained MAGVIT V2 and SoundStream tokenizers, which translate images, video, and audio clips into a sequence of codes that the model can understand.
- An autoregressive language model, which learns from various modalities—video, image, audio, and text—to predict the next token in the sequence.
- A range of generative learning objectives, including text-to-video, text-to-image, image-to-video, and more, which enable VideoPoet to create diverse and high-quality videos.
Revolutionary Features and Capabilities
Like Sora and Stable Diffusion, VideoPoet has some revolutionary features that bring a fresh perspective to video creation.
High-Motion Variable-Length Videos: Unlike traditional models, VideoPoet effortlessly crafts high-motion variable-length videos, pushing the boundaries of what’s possible in video generation.
Cross-Modality Learning: One of VideoPoet’s strengths lies in its ability to learn across different modalities. By bridging the gap between text, images, videos, and audio, VideoPoet offers a holistic understanding that enriches the creative process.
Interactive Editing Capabilities: VideoPoet doesn’t just generate videos—it empowers users with interactive editing features. From extending input videos to controlling motions and applying stylized effects based on text prompts, it puts creative control in the hands of the user.
Google’s VideoPoet is more than just a video generation tool—it’s a game-changer in the world of AI. By seamlessly integrating multiple capabilities into a single large language model (LLM), it redefines the landscape of video generation. Its versatility in processing text, image, and audio makes it indispensable for content creators and AI enthusiasts alike, setting a new standard for creativity and innovation.
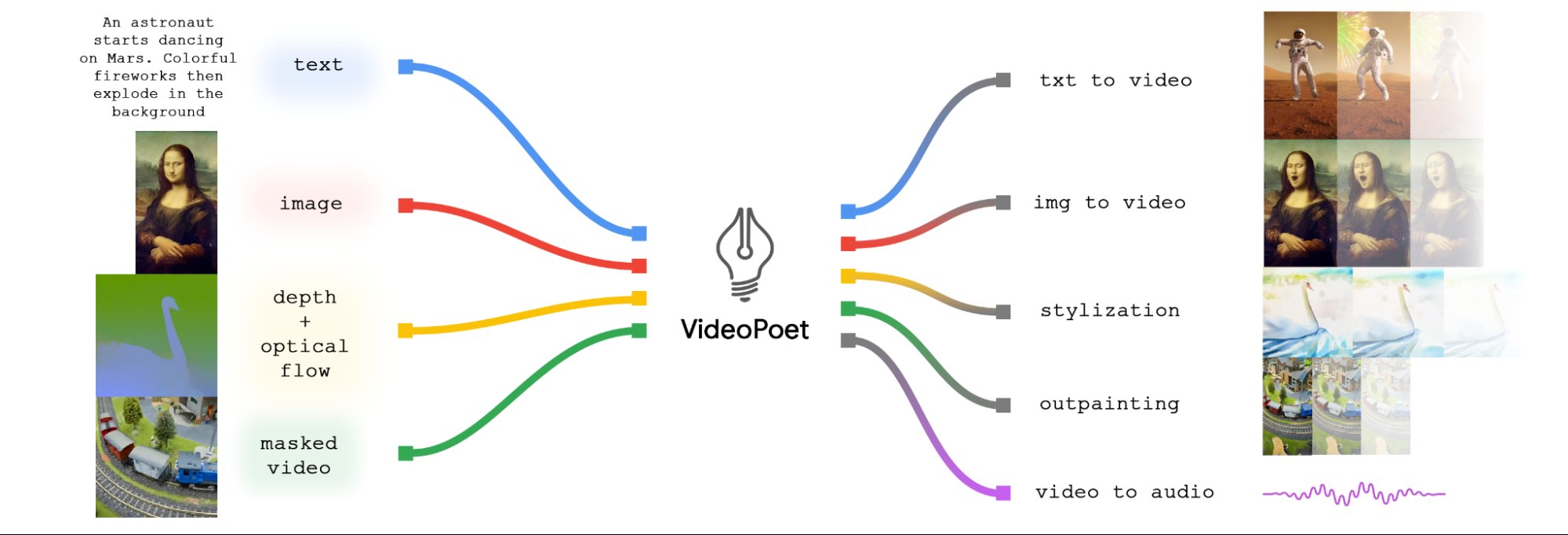
Here’s a breakdown of VideoPoet’s capabilities using the diagram below.
First off, input images can be brought to life with animation, creating dynamic motion within the video. Additionally, users have the option to edit videos by cropping or masking certain areas, allowing for seamless inpainting or outpainting effects.
When it comes to stylization, the model works its magic by analyzing a video that captures depth and optical flow—essentially, the motion within the scene. Using this information, it applies stylistic elements guided by text prompts, enhancing the overall visual appeal of the video.
But enough technical jargon—let’s talk results. To showcase VideoPoet’s capabilities, the Google Research team produced a short film based on prompts from Bard, a storytelling AI. The result? A charming tale of a traveling raccoon, brought to life through a series of captivating video clips. It’s a testament to the power of AI in storytelling, and a glimpse into the future of multimedia creation.
In a world where content is king, tools like Sora and VideoPoet are changing the game, empowering creators to bring their ideas to life in ways never before possible. With their advanced capabilities and user-friendly interfaces, these AI-driven tools are poised to revolutionize how we tell stories and express ourselves through video.